Please review the QC test results indicated by  icon below as well as clone information before placing your order.
icon below as well as clone information before placing your order.
提供案内 (日本国内)  [open/close]
[open/close]
Please review the QC test results indicated by icon below as well as clone information before placing your order.
pAx1-CAh-tPA (#RDB01706)
Shuttle vector to generate rAd expressing human tissue plasminogen activator
| Clone info. | Shuttle vector to generate recombinant adenovirus vector expressing human tissue plasminogen activator gene. cDNA fragment 258 to 2138nt of NM_000930.4 (CDS, 258 to 1946nt) is cloned. |
|---|---|
| Comment | Use the COS-TPC method for production of adenovirus. Known difference (at least): C to T substitution at 758nt (Ala, synonym). |
| Vector backbone | pAxcw (Cosmid, use packaging extracts for transforming E. coli host) |
| Size of vector backbone | 42.5 kb |
| Selectable markers | Amp^r |
| Gene/insert name | Human Tissue plasminogen activator (tPA) cDNA |
| Depositor|Developer | Hamada, Hirofumi | |
| Additional map | 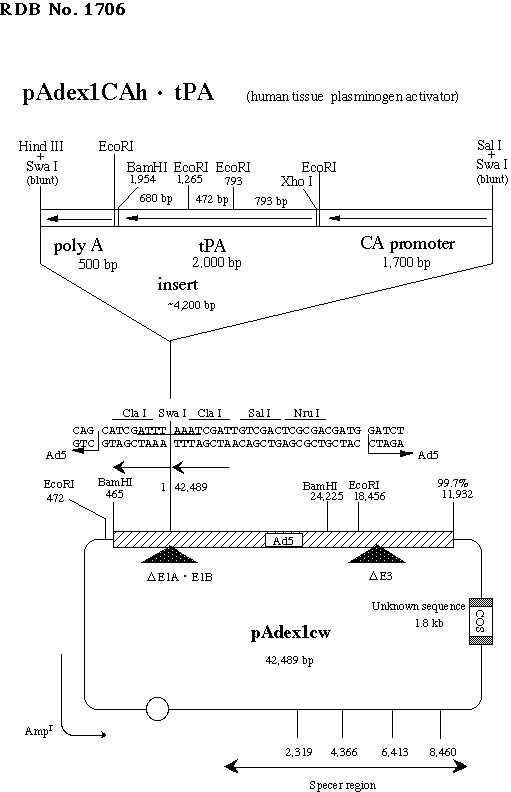
|
|---|
Distribution information
Please check terms and conditions set forth by the depositor, which are specified in the RIKEN BRC Catalog and/or Web Catalog.
| Ordering forms | Order form [Credit Card Payment MTA, for use for not-for-profit academic purpose [Word Please visit Information of Request for Distribution.[link] |
|---|---|
| Terms and conditions for distribution | The availability of the BIOLOGICAL RESOURCE is limited to a RECIPIENT of a not-for profit institution for a not-for-profit research. RECIPIENT must contact the DEPOSITOR in the case of application for any patents or commercial use based on the results from the use of the BIOLOGICAL RESOURCE. In publishing the research results obtained by use of the BIOLOGICAL RESOURCE, a citation of the following literature designated by the DEPOSITOR (J. Leukoc. Biol., 60, 181-190 (1996).) and an acknowledgment to the DEPOSITOR are requested. Additional terms and conditions: Regarding resources containing CAG promoter: In publishing the research results obtained by use of the BIOLOGICAL RESOURCE, a citation for the CAG promoter (Niwa, H., Yamamura, K., Miyazaki, J., Gene 108 : 193-200, 1991) and an acknowledgment to Dr. Jun-ich Miyazaki of the Osaka University are requested. |
| Remarks | Remember that you will be working with samples containing infectious virus. |
[open/close]| 必要書類 | 提供依頼書 提供同意書 (MTA, 非営利学術目的用)[Word 手続きの概要は、「提供申込みについて[link]」をご覧ください。 |
|---|---|
| MTAに書く使用条件 | 非営利機関の非営利学術研究へ提供する。利用者が本件リソースを利用した研究成果に基づき特許申請、商業活動等を行う場合は、利用者は事前に寄託者に連絡する。利用者は、研究成果の公表にあたって寄託者の指定する文献 (J. Leukoc. Biol., 60, 181-190 (1996).) を引用し、謝辞の表明を必要とする。 MTAに書く付加的使用条件: CAGプロモータを含むリソースについて: 利用者は、研究成果の公表にあたってCAGプロモータの文献 (Niwa, H., Yamamura, K., Miyazaki, J., Gene 108 : 193-200, 1991)を引用し、大阪大学 宮崎純一博士への謝辞の表明を必要とする。 |
| 備考 | このリソースはウイルス粒子産生用のため、取扱いに注意が必要です。 |
| Catalog # | Resource name | Shipping form | Fee (non-profit org.) |
|---|---|---|---|
| RDB01706 | pAx1-CAh-tPA | DNA solution |
JPY 9,460 (not-for-profit academic purpose) plus cost of shipping containers, dry ice (if required) and shipping charge |
How to cite this biological resource
Materials & Methods section:
| The pAx1-CAh-tPA was provided by the RIKEN BRC through the National BioResource Project of the MEXT, Japan (cat. RDB01706). |
Reference section:
Further references such as user reports and related articles (go to bottom)
QC test results
RIKEN BRC has sequenced portions of this material for quality test.
Please review the QC test results indicated by ![]() icon as well as clone information before placing your order.
icon as well as clone information before placing your order.
| Test sheet | RDB15035_A7Egp1.pdf |
|---|
Nucleotide sequence of a portion of this resource (if available).
|
Primer: pAxCA_F1 Sequence file: RDB15035_A7Ega.seq |
|---|
|
>01706_15035_A7Eg_2_pAxCA_F1_D05_11_ABI24.ab1 1 CGTTCCCTTT CCTCCCATGT TCATGCCTTC TTCTTTTTCC TACAGCTCCT GGGCAACGTG 61 CTGGTTATTG TGCTGTCTCA TCATTTTGGC AAAGAATTCG CGCGTAATAC GACTCACTAT 121 AGGGCGAATT GGGTACCGGG CCCCCCCTCG AGATGGATGC AATGAAGAGA GGGCTCTGCT 181 GTGTGCTGCT GCTGTGTGGA GCAGTCTTCG TTTCGCCCAG CCAGGAAATC CATGCCCGAT 241 TCAGAAGAGG AGCCAGATCT TACCAAGTGA TCTGCAGAGA TGAAAAAACG CAGATGATAT 301 ACCAGCAACA TCAGTCATGG CTGCGCCCTG TGCTCAGAAG CAACCGGGTG GAATATTGCT 361 GGTGCAACAG TGGCAGGGCA CAGTGCCACT CAGTGCCTGT CAAAAGTTGC AGCGAGCCAA 421 GGTGTTTCAA CGGGGGCACC TGCCAGCAGG CCCTGTACTT CTCAGATTTC GTGTGCCAGT 481 GCCCCGAAGG ATTTGCTGGG AAGTGCTGTG AAATAGATAC CAGGGCCACG TGCTACGAGG 541 ACCAGGGCAT CAGCTACAGG GGCACGTGGA GCACAGCGGA GAGTGGCGCC GAGTGCACCA 601 ACTGGAACAG CAGCGCGTTG GCCCAGAAGC CCTACAGCGG GCGGAGGCCA GATGCCATCA 661 GGCTGGGCCT GGGGAACCAC AACTACTGCA GAAACCCAGA TCGAGACTCA AAGCCCTGGT 721 GCTACGTCTT TAAGGCGGGG AAGTACAGCT CAGAGTTCTG CAGCACCCCT GCCTGCTCTG 781 AGGGAAACAG TGACTGCTAC TTTGGGAATG GGTCAGCCTA CCGTGGCACG CACAGCCTCA 841 CCGAGTCGGG TGCCTCCTGC CTCCCGTGGA ATTCCATGAT CCCTGAATAG GCAAGGTTTA 901 CACAGCACAG AAACCCCAGG TGCCCAAGGC ACTGGGCCTG GGCAAACATA ATTACTGCCG 961 GAATCCTGAT GGGGATGCCA AGCCCTTGTT GCCACGTGCT GAAGAACCGC AGCTGACGTG 1021 GGAGTACTGG TGATGGTGCC CTCCTGCTCC ACCTGGCGGC TGGAGACAAG TACAGCCAGG 1081 CTCAGGTTCC GCATTCAAGG AGGCTCTTCG GCGGACTCGC TCCAACCCCT GCAGCTGCCA 1141 TCATGCCAAG CCTGAAGTCG CTTTAGGTTC CTGTAGCGGG GCCAATAACC TCAA // |
|
Primer: pAxCA_R1 Sequence file: RDB15035_A7Egb.seq |
|
>01706_15035_A7Eg_2_pAxCA_R1_C07_07_ABI24.ab1 1 GGGGAACAGG GGCATTGGCC ACAACCAGCC ACCACCTTCT GATAGGCAGC CTGCACCTGA 61 GGAGTGAATT CGCGCAATTA ACCCTCACTA AAGGGAACAA AAGCTGGAGC TCCACCGCGG 121 TGGCGGCCGC TCTAGAACTA GTGGATCCCC CAAGTCCTGA AAACTTCCAA AATGGGAAGT 181 ATCTGGGAAA ATGCACTCTT CCCTCTCCTG TAGGGTCTCG TCCCGCTTCT GCGGTGTGGT 241 GGGTCTGGAG AAGTCTGTAG AGAAGCACTG CGCCTTTGCA GTGTCTTCTG AAGAAGAAGA 301 GGCGGGATCT CATTTGCTTT TGAGGAGTCG GGTGTTCCTG GTCACGGTCG CATGTTGTCA 361 CGAATCCAGT CTAGGTAGTT GGTAACCTTG GTGTACACAC CCGGGACATC CTTCTGTCCA 421 CAGCCCAGGC CCCAGCTGAT GATGCCCACC AAAGTCATGC GGCCATCGTT CAGACACACC 481 AGGGGGCCTC CCGAATCGCC CTGGCAGGCG TCGTGCAAGT TTGCCTGGGG CCCGCCGCTC 541 CGAGTGTCTC CAGCACACAG CATGTTGTCG GTGACTGTTC TGTTAAGTAA ATGTTGTGAT 601 GTGCAGCGGC TGGATGGGTA CAGTCTGACA TGAGCCTCCT TCAGCCGCTC CGAATAGAAA 661 GGAGACAAGG CCTCATGCTT GCCGTAGCCG GAGAGCTCAC ACTCCGTCCA GTCCGGCAGC 721 TGCAGGTCCG CCGGGGGAAG GCACACAGTG CGGACCACGC TGCTCTCCTG GGCACAGCGG 781 GACGAATCCG ATTTCAGCTG CAGCAGCGCA ATGTCATTGT CGTAAGTGTC ATCATCGAAT 841 TCCTTATGGA CAATGTATTT TTCGACTTCA AATTTCTGCT CCTCCTCGCC AGGGACCACC 901 CGGTATGTTC TGCCCAAGAT CACCGTCAGG TGGTGGGGCG GAAACCTCTC CTGGAAGCAG 961 TGGGCGGCAG AGAGAATCCA GCAGGAGCTG ATGAGTATGC CCCCGCACAG GAACCGCTCT 1021 CCGGGCGACC TCCTGTGCTT TGCAAAGATG GCAGCCTGCC CAGGGGTGGG AGGCGATGTC 1081 GGCGAAGAAG CCCTCTTTTG ATGCGAACTG AGCCTGGGCT TGTACTGTCT CAAGGCGGCA 1141 AGTGGAAGCA GGAGGCACAT CCACAGTTTA ACTCTCCCAC ACGGTTTCAG GCCCC // |
|
Primer: pAxcwit2-Fw Sequence file: RDB15035_A7Egc.seq |
|
>01706_15035_A7Eg_2_pAxcwit2_Fw_A07_01_ABI24.ab1 1 CACTAGCGCG GGGTGCAGGC CAGCACCAAG TGATCGGGCC TCAGCTCCTC GGTCACATCC 61 AGCATCACAG GCTGGTTCCT AATATGTTTA CCGCCACACT CGCAGGGTCT GCACCTGGTG 121 CGGGTCTCAT CGTACCTCAG CACCTTCCAG ATCCATCGTC GCGAGTCGAC AATCGATTTT 181 CGACATTGAT TATTGACTAG TTATTAATAG TAATCAATTA CGGGGTCATT AGTTCATAGC 241 CCATATATGG AGTTCCGCGT TACATAACTT ACGGTAAATG GCCCGCCTGG CTGACCGCCC 301 AACGACCCCC GCCCATTGAC GTCAATAATG ACGTATGTTC CCATAGTAAC GCCAATAGGG 361 ACTTTCCATT GACGTCAATG GGTGGAGTAT TTACGGTAAA CTGCCCACTT GGCAGTACAT 421 CAAGTGTATC ATATGCCAAG TACGCCCCCT ATTGACGTCA ATGACGGTAA ATGGCCCGCC 481 TGGCATTATG CCCAGTACAT GACCTTATGG GACTTTCCTA CTTGGCAGTA CATCTACGTA 541 TTAGTCATCG CTATTACCAT GGTCGAGGTG AGCCCCACGT TCTGCTTCAC TCTCCCCATC 601 TCCCCCCCCT CCCCACCCCC AATTTTGTAT TTATTTATTT TTTAATTATT TTGTGCAGCG 661 ATGGGGGCGG GGGGGGGGGG GGGGCGCGCG CCAGGCGGGG CGGGGCGGGG CGAGGGGCGG 721 GGCGGGGCGA GGCGGAGAGG TGCGGCGGCA GCCAATCAGA GCGGCGCGCT CCGAAAGTTT 781 CCTTTTATGG GCGAGG // |
|
Primer: Amp_R Sequence file: RDB15035_A7Egd.seq |
|
>01706_15035_A7Eg_2_Amp_R_B07_04_ABI24.ab1 1 CTCGTTTCAT ATTATTGAAG CATTTATCAG GGTTATTGTC TCATGAGCGG ATACATATTT 61 GAATGTATTT AGAAAAATAA ACAAATAGGG GTTCCGCGCA CATTTCCCCG AAAAGTGCCA 121 CCTGACGTCT AAGAAACCAT TATTATCATG ACATTAACCT ATAAAAATAG GCGTATCACG 181 AGGCCCTTTC GTCTTCAAGA ATTCCGGATC CGGGCCAATA TGATAATGAG GGGGTGGAGT 241 TTGTGACGTG GCGCGGGGCG TGGGAACGGG GCGGGTGACG TAGTAGTGTG GCGGAAGTGT 301 GATGTTGCAA GTGTGGCGGA ACACATGTAA GCGACGGATG TGGCAAAAGT GACGTTTTTG 361 GTGTGCGCCG GTGTACACAG GAAGTGACAA TTTTCGCGCG GTTTTAGGCG GATGTTGTAG 421 TAAATTTGGG CGTAACCGAG TAAGATTTGG CCATTTTCGC GGGAAAACTG AATAAGAGGA 481 AGTGAAATCT GAATAATTTT GTGTTACTCA TAGCGCGTAA TATTTGTCTA GGGCCGCGGG 541 GACTTTGACC GTTTACGTGG AGACTCGCCC AGGTGTTTTT CTCAGGTGTT TTCCGCGTTC 601 CGGGTCAAAG TTGGCGTTTT ATTATTATAG TCAGCATCGA TTAGCTTGGG CTGCAGGTCG 661 AGGGATCTCC ATAAGAGAAG AGGGACAGCT ATGACTGGGA GTAGTCAGGA GAGGAGGAAA 721 AATCTGGCTA GTAAAACATG TAAGGAAAAT TTTAGGGATG TTAAAGAAAA AAATAACACA 781 AAACAAAATA TAAAAAAAAT CTAACCTCAA GTCAAGGCTT TTCTATGGAA TAAGGAATGG 841 ACAGCAGGGG GCTGTTTCAT ATACTGATGA CCTCTTTATA GCCAACCTTT GTTCATGGCA 901 GCCAGCATAT GGGCATATGT TGCCAAACTC TAAACCAAAT ACTCATTCTG ATGTTTTAAA 961 TGATTTGCCC TCCATATGTC CTTCCGAGTG AGAGACACAA AAAATTCCAA CACACTATTG 1021 CAATGAAAAT AAATTTCTTT ATTAGCCAGA AGTCAGATGC TCAGGGCCTC ATGATGTCCC 1081 CATAATTTTG CGAGGGAAAA GATCTCAGTG TATTGTGAAC CAAGCAATGG ACAACAAGCA 1141 ACAACATTCT GAAATAGGCA GGCCTGGCAC // |
Please visit  Sequencing and PCR primers for primer information.
Sequencing and PCR primers for primer information.
References
Original, user report and related articles
Resource search
Link
Other resources in our bankExternal Database
Human Tissue plasminogen activator (tPA)
Reference sequence
Tips
Featured content




